Using the Backoffice UI¶
The backoffice is Kaval.AI’s management and monitoring UI — a FastAPI service
(kavalai.backoffice) backed by PostgreSQL, with an Angular front end. While
the SDK runs your agents, the backoffice is where you configure, inspect and
observe them: every session, run, node and model call your workflows produce is
recorded and browsable here. It is the visual side of Kaval.AI’s observable
pillar.
Running it locally¶
The repository ships a docker-compose.yml that brings up PostgreSQL, runs the
migrations and starts the backoffice:
docker compose up postgres_db backoffice-migrations backoffice
The UI is then served at http://localhost:8000. Agents write their runs into
the same database (the agents schema), so anything you execute with the SDK
shows up in the views below.
Projects¶
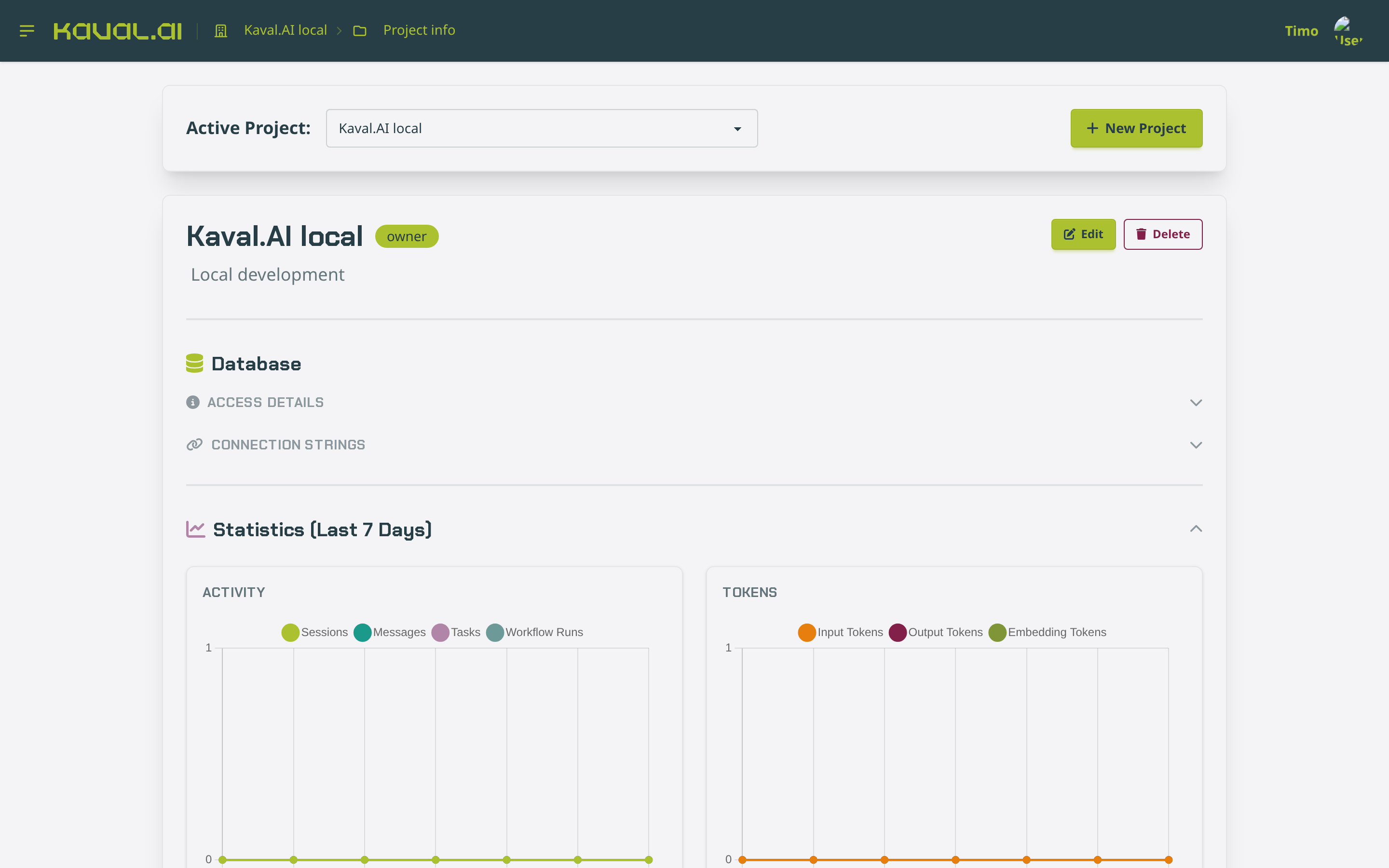
Everything in the backoffice is scoped to a project. A project points at an agent database (host, port, schema) and carries its own members and statistics, so you can separate environments — local, staging, production — behind one UI. The landing page lets you switch the active project, create new ones, and inspect a project’s database connection and recent activity.
Agents¶
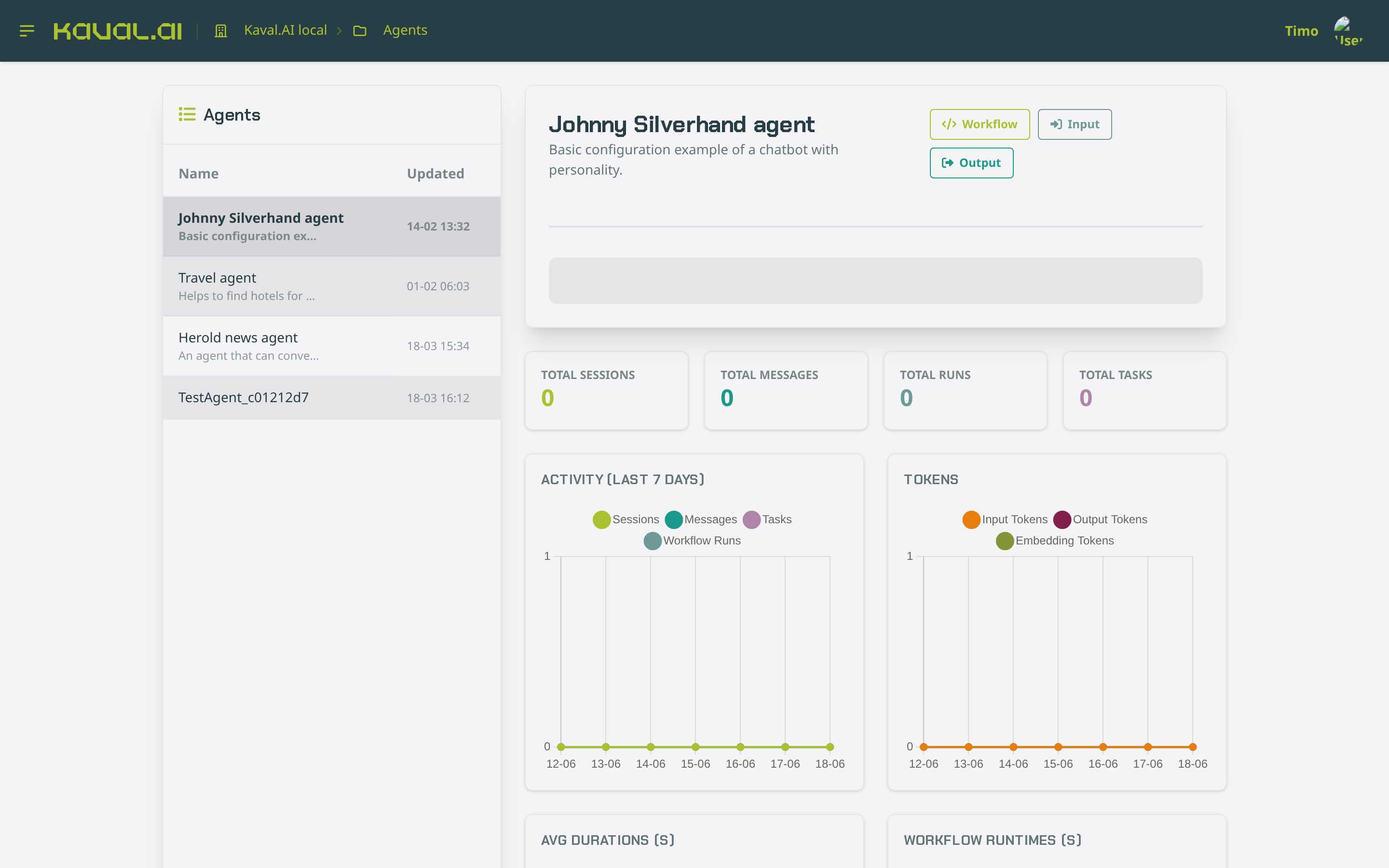
The Agents page lists the configured agents in the active project. Selecting one shows its workflow definition (open the Workflow, Input and Output views), along with headline counters — total sessions, messages, runs and tasks — and seven-day activity and token charts. This is the quickest way to see how a single agent is being used.
Workflow monitoring¶
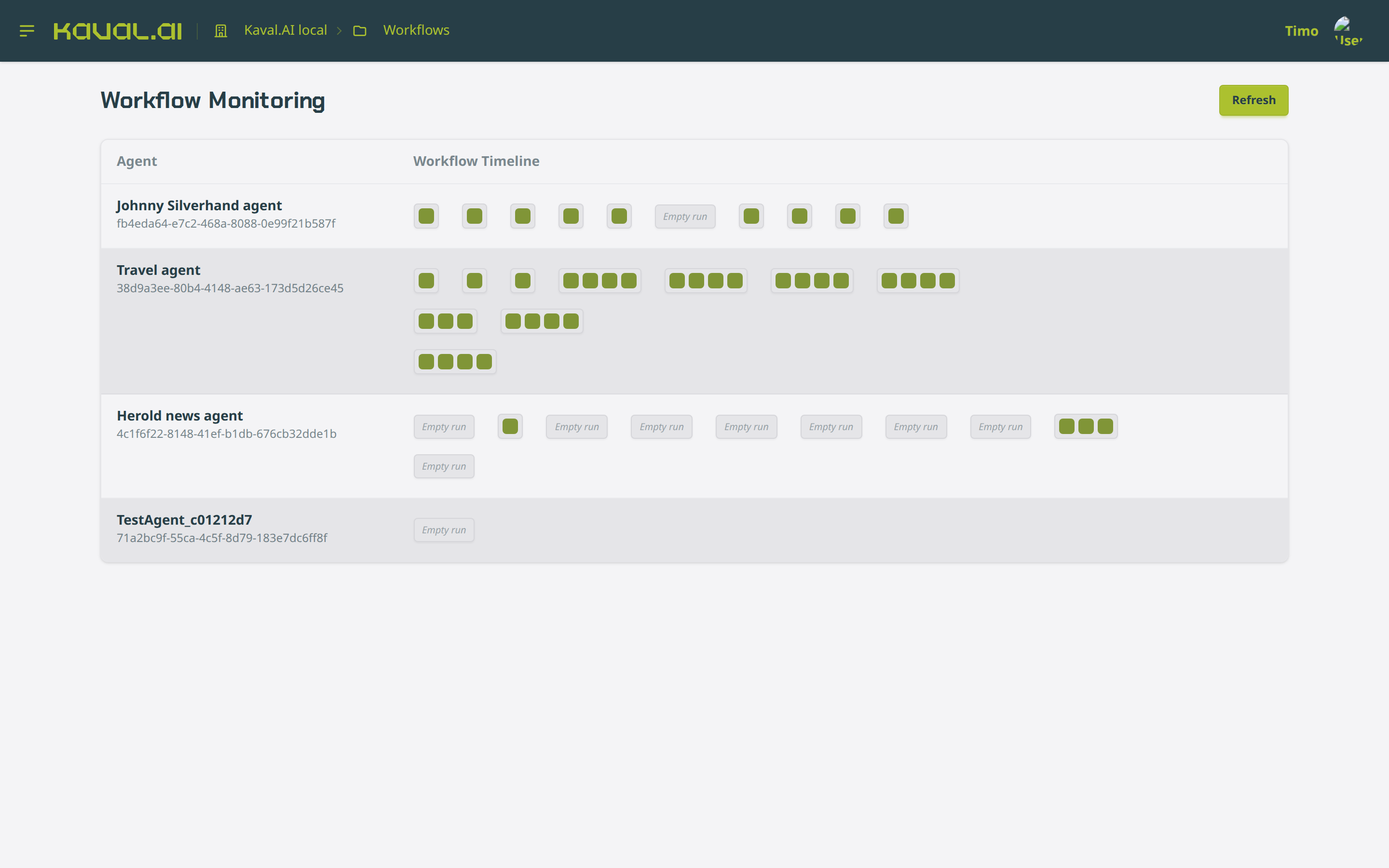
The Workflows page is a live monitoring timeline: one row per agent, each square a recent run. Completed runs are filled; empty runs are flagged. It gives an at-a-glance health view across all agents and a jumping-off point into individual runs.
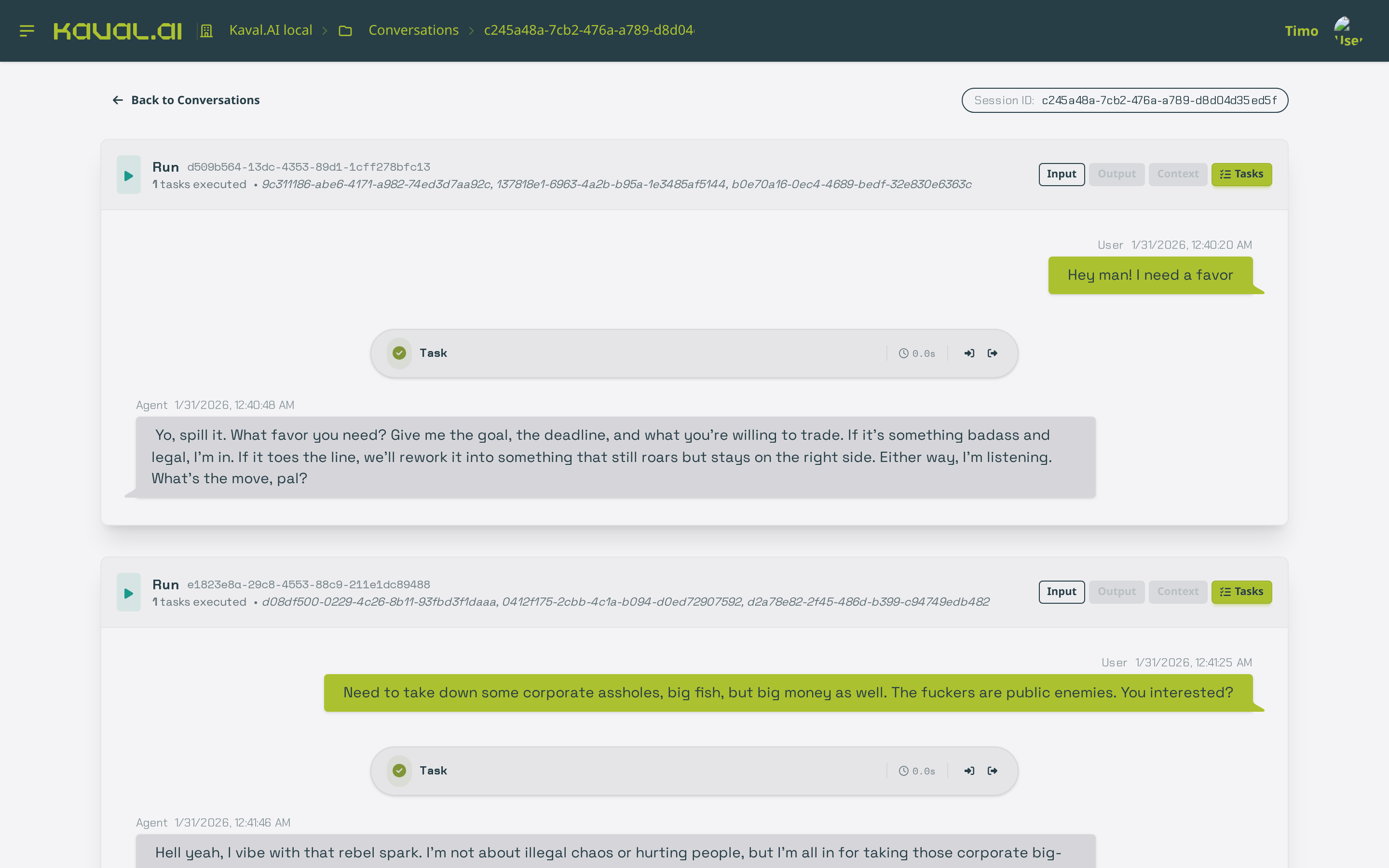
Conversations, runs and tasks¶
This is the heart of observability. A conversation (session) groups the runs triggered within it; each run expands into the ordered tasks (the nodes the engine executed). You can read the chat turns, and for any run open its Input, Output and per-node Tasks — exactly the data the engine checkpointed through its storage and task-logger backends (see Observability).
Drilling into a conversation shows each run, the tasks it executed, and the full message history:
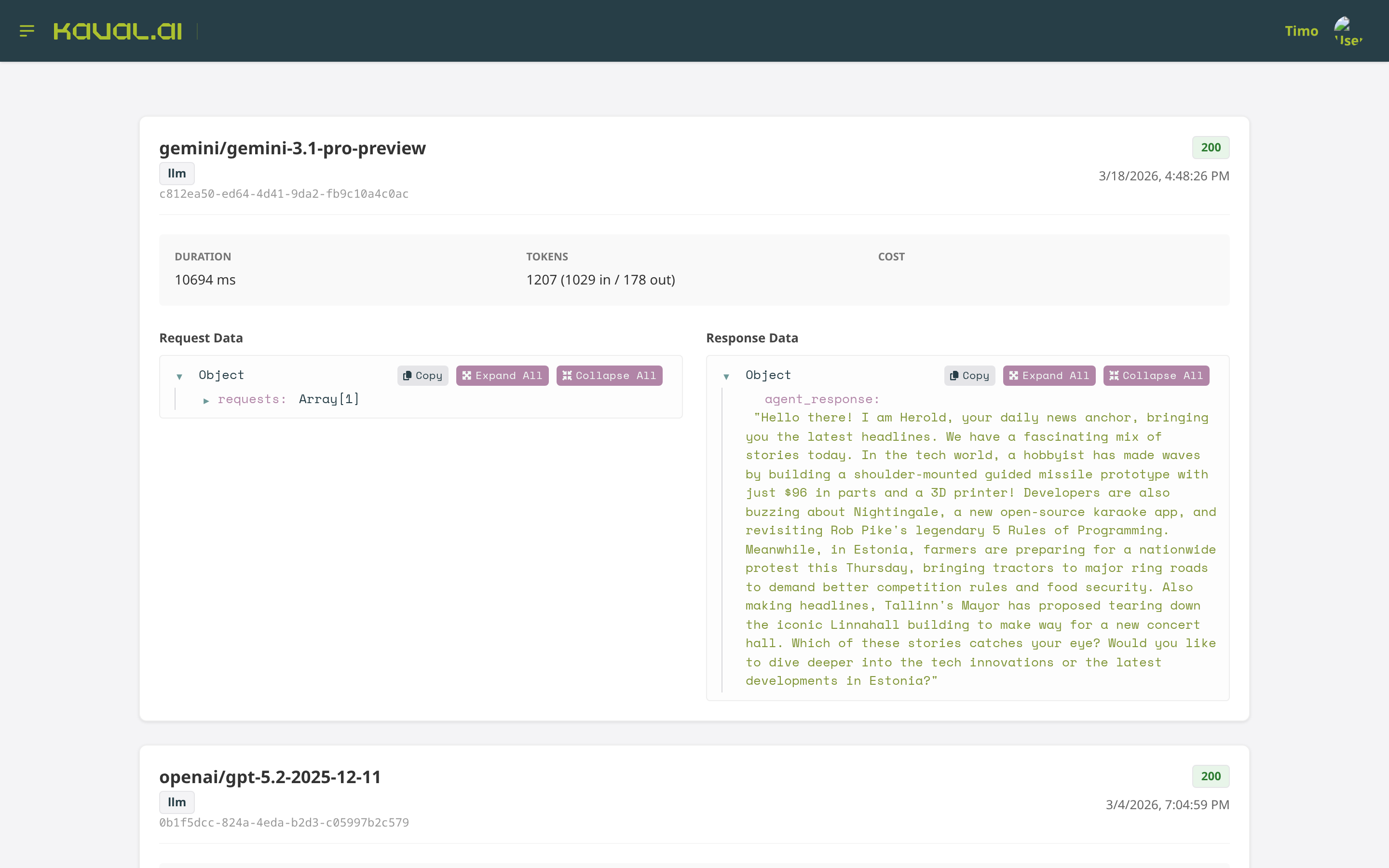
Model calls¶
The Model Calls page lists every LLM and embedding call: the provider/model,
status, duration, token usage (prompt vs. completion) and the exact request and
response payloads. Each row corresponds to a ModelCallStat
recorded at runtime — invaluable for debugging prompts, auditing behaviour and
tracking spend.
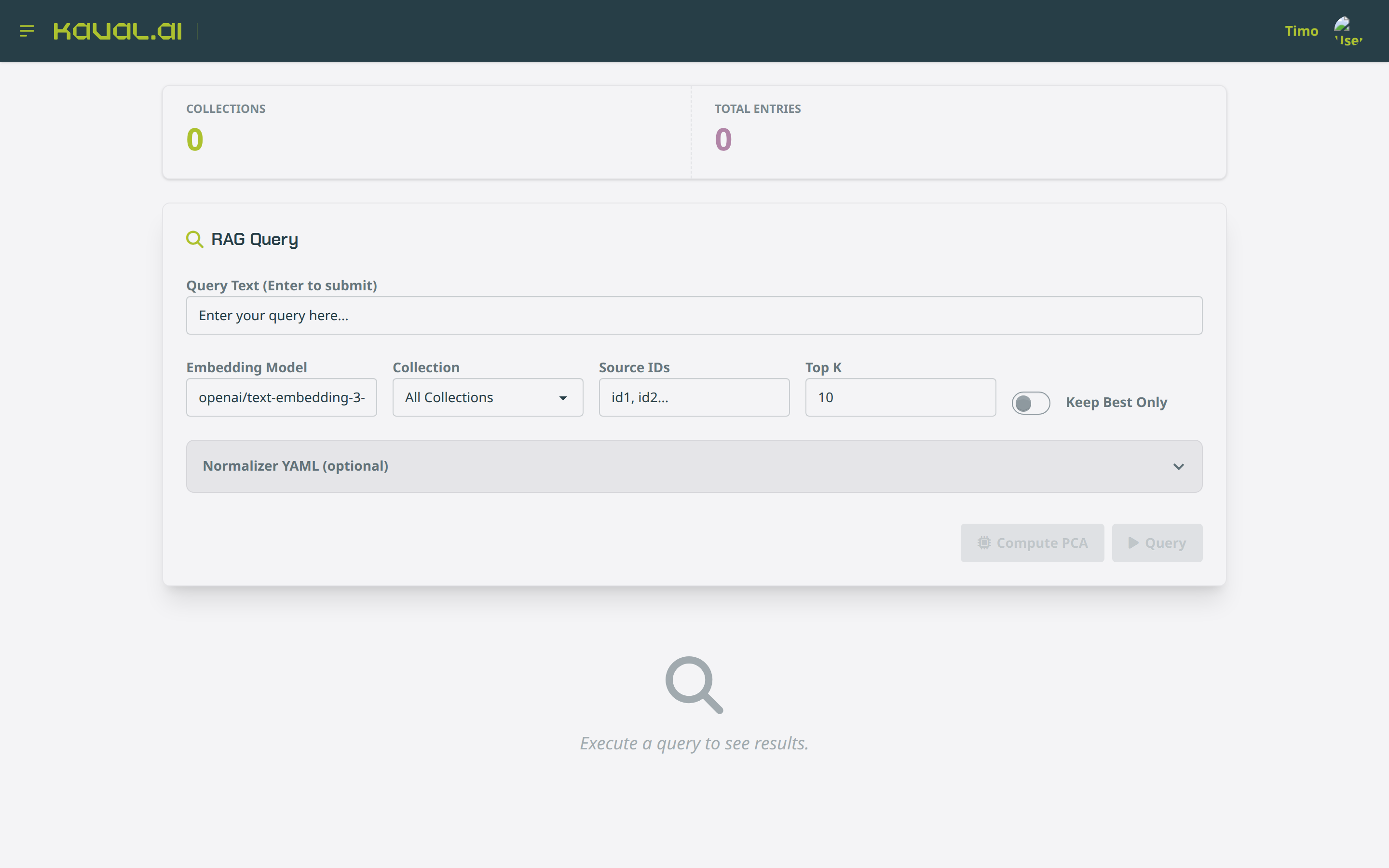
RAG explorer¶
The RAG page inspects and queries the project’s vector collections. Enter a
query, choose an embedding model and collection, set top-k, and review the
nearest matches; you can also compute a PCA projection of the embedding space.
It is the UI counterpart to RagService.
Users and access¶
Administrators can manage users and per-project memberships (owner / member), controlling who can see and edit each project. Sign-in is handled via OAuth, and project-scoped endpoints enforce membership server-side.